Audio Style Transfer using Generative Adversarial Networks
HCI Lab - Seoul National University (2017)
Generative Adversarial Networks (GANs) have gained their popularity in image style transfer by showing impressive results such as DiscoGAN [1] and CycleGAN [2]. In this small project we test and explore the use of GAN in the domain of audio style transfer (i.e., transferring a sound of one instrument to another).
Our Approach
We first converted each audio data to a spectrogram via Short Time Fourier Transform (STFT) and fed it to the network as 2D image. In order to use unlabeled data and prevent mode collapsing, we adopted the design of CycleGAN and modified it as below. Note that we found leaky ReLu to be the most effective activation function for the generator.
We first converted each audio data to a spectrogram via Short Time Fourier Transform (STFT) and fed it to the network as 2D image. In order to use unlabeled data and prevent mode collapsing, we adopted the design of CycleGAN and modified it as below. Note that we found leaky ReLu to be the most effective activation function for the generator.
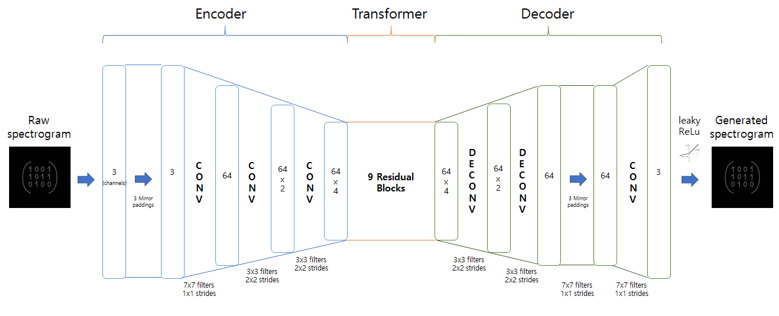
An architecture of the generator which is based on CycleGAN.
The NSynth Dataset
It is a large-scale and high-quality dataset which contains single note audio files of various instruments. We used it to verify whether our model can transfer between instruments while retaining the pitch.
After testing many different combinations of instruments, we found an interesting pattern that is dependent on the characteristic of each instrument. For example, when we trained our model using flute and base sounds, it worked well on the low pitch but not on the high pitch. We believe this was mainly caused by the differences in the range of notes each instrument can play; the base dataset only had low pitch sounds while flute dataset had wider range of sounds.
It is a large-scale and high-quality dataset which contains single note audio files of various instruments. We used it to verify whether our model can transfer between instruments while retaining the pitch.
After testing many different combinations of instruments, we found an interesting pattern that is dependent on the characteristic of each instrument. For example, when we trained our model using flute and base sounds, it worked well on the low pitch but not on the high pitch. We believe this was mainly caused by the differences in the range of notes each instrument can play; the base dataset only had low pitch sounds while flute dataset had wider range of sounds.
- Low pitch example: [Original flute sound] => [Transferred base sound] 😀
- High pitch example: [Original flute sound] => [Transferred base sound] ☹️
IRMAS Dataset & Speech Data
Just for fun, we also tried to transfer between a sound of an instrument and a speech of a person. We used IRMAS dataset which contains multiple notes played many different instruments. For the speech data, we collected 233 minutes of speech of Sohn Suk Hee (one of the most popular news anchor in Korea) from Youtube.
Of course the transferred results don't sound nice, but we can hear that the model is kind of trying to demonstrate some of the characteristics of the target instrument or speech. Here are some of the examples we trained using piano and speech.
Just for fun, we also tried to transfer between a sound of an instrument and a speech of a person. We used IRMAS dataset which contains multiple notes played many different instruments. For the speech data, we collected 233 minutes of speech of Sohn Suk Hee (one of the most popular news anchor in Korea) from Youtube.
Of course the transferred results don't sound nice, but we can hear that the model is kind of trying to demonstrate some of the characteristics of the target instrument or speech. Here are some of the examples we trained using piano and speech.
- Speech to piano: [Original speech] => [Transferred piano sound]
- Piano to speech: [Original piano sound] => [Transferred speech]
References
[1] Kim, Taeksoo, et al. "Learning to discover cross-domain relations with generative adversarial networks." arXiv preprint arXiv:1703.05192 (2017).
[2] Zhu, Jun-Yan, et al. "Unpaired image-to-image translation using cycle-consistent adversarial networks." arXiv preprint (2017).
[2] Zhu, Jun-Yan, et al. "Unpaired image-to-image translation using cycle-consistent adversarial networks." arXiv preprint (2017).
